The optimization goals of the DeepSeek-V3 / R1 inference system are: higher throughput and lower latency.
To achieve these two goals, Deepseek's solution is to use large-scale cross-node expert parallelism (Expert Parallelism / EP). First, EP greatly increases the batch size, thereby improving the efficiency of GPU matrix multiplication and improving throughput. Second, EP allows experts to be dispersed on different GPUs, and each GPU only needs to calculate a small number of experts (thus requiring less memory access), thereby reducing latency.
However, EP also increases the complexity of the system. The complexity is mainly reflected in two aspects:
- EP introduces cross-node transmission. In order to optimize throughput, it is necessary to design a suitable computing process so that transmission and computing can be performed synchronously.
- EP involves multiple nodes, so Data Parallelism (DP) is naturally required, and load balancing is required between different DPs.
Therefore, the main content of this article is how to use EP to increase the batch size, how to hide the transmission time, and how to perform load balancing .
Large-scale cross-node expert parallelism (Expert Parallelism / EP)
Since DeepSeek-V3 / R1 has a large number of experts and only 8 out of 256 experts are activated in each layer, the high sparsity of the model means that Deepseek must use a large overall batch size to provide each expert with enough expert batch size, thereby achieving higher throughput and lower latency. This requires large-scale cross-node expert parallelism (Expert Parallelism / EP).
Deepseek use an expert parallel strategy across multiple machines and multiple cards to achieve the following goals:
- Prefill : Routing Expert EP32, MLA and Shared Expert DP32, one deployment unit is 4 nodes, 32 redundant routing experts, 9 routing experts and 1 shared expert per card
- Decode : Routing Expert EP144, MLA and Shared Expert DP144, one deployment unit is 18 nodes, 32 redundant routing experts, 2 routing experts and 1 shared expert per card
Calculating Communication Overlap
The parallel processing of experts on multiple machines and multiple cards will introduce relatively large communication overhead, so Deepseek use double batch overlap to cover the communication overhead and improve the overall throughput.
In the prefill phase, the computation and communication of the two batches are interleaved, so that the computation of one batch can cover the communication overhead of the other batch.
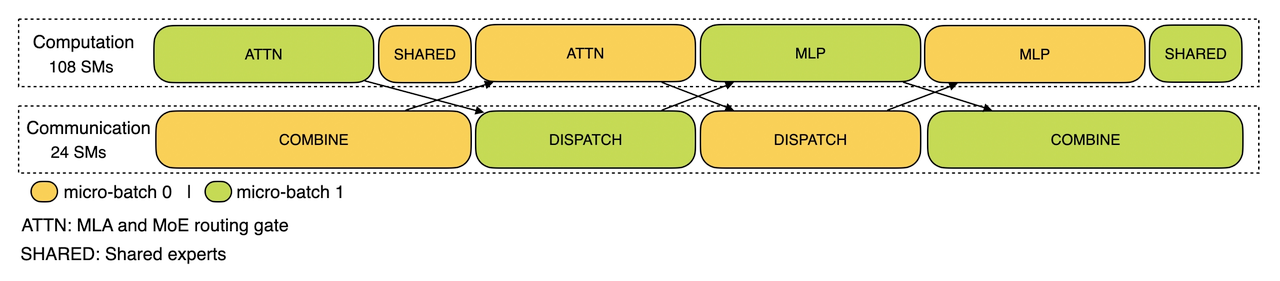
For the decoding stage, the execution time of different stages is different, so Deepseek split the attention part into two stages, a total of 5 stages of the pipeline to achieve the overlap of calculation and communication.
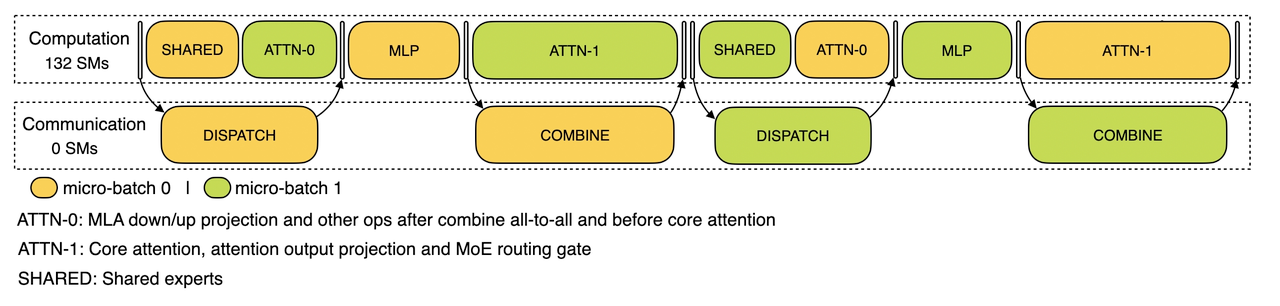
For more details about double batch overlap, please refer to our profiling data GitHub repository : https://github.com/deepseek-ai/profile-data.
Load balance as much as possible
Due to the large-scale parallelism (including data parallelism and expert parallelism), if the computation or communication load of a GPU is too heavy, it will become a performance bottleneck and slow down the entire system; at the same time, other GPUs will idle due to waiting, resulting in a decrease in overall utilization. Therefore, Deepseek need to distribute a balanced computation load and communication load to each GPU as much as possible.
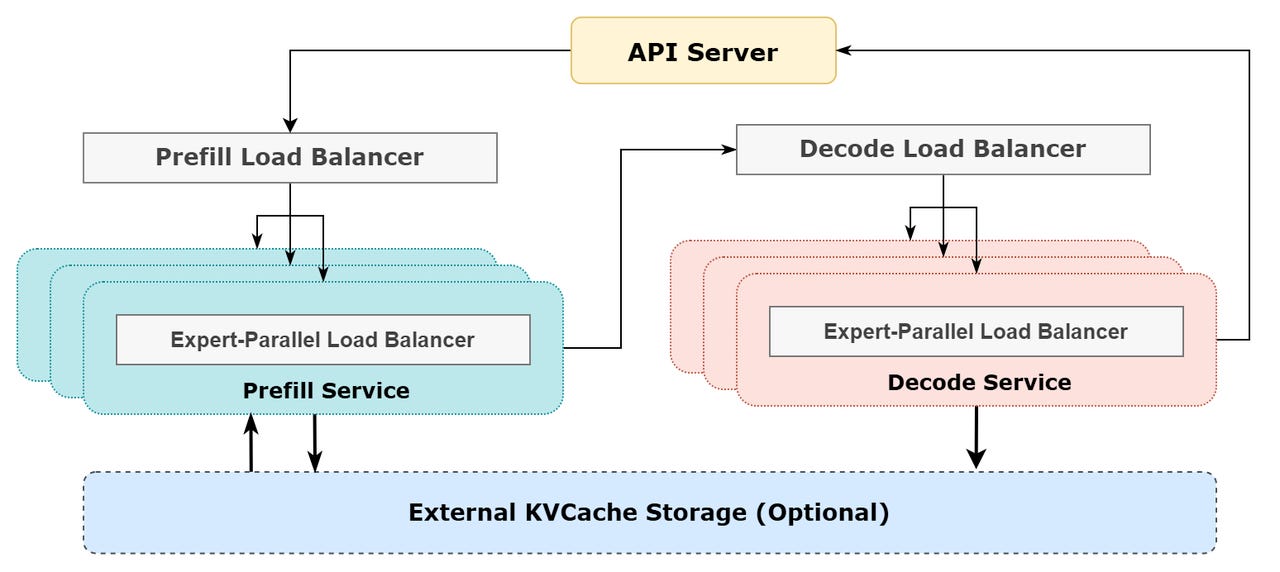
- Prefill Load Balancer
- Core problem: The number and length of requests on different data parallel (DP) instances are different, resulting in different core-attention calculations and dispatch sending volumes.
- Optimization goal: Make the computational load of each GPU as similar as possible (core-attention computation load balancing), and the number of input tokens as similar as possible (dispatch sending load balancing), to avoid some GPUs taking too long to process.
- Decode Load Balancer
- Core problem: The number and length of requests on different data parallel (DP) instances are different, resulting in different core-attention calculations (related to KVCache occupancy) and dispatch sending volumes.
- Optimization goal: Make the KVCache usage of each GPU as similar as possible (core-attention calculation load balancing), and the number of requests as similar as possible (dispatch sending load balancing)
- Expert-Parallel Load Balancer
- Core problem: For a given MoE model, there are some natural high-load experts, which leads to unbalanced expert computing loads on different GPUs.
- Optimization goal: Balance the expert computing amount on each GPU (that is, minimize the maximum value of the dispatch receiving amount of all GPUs)
Reference Architecture Diagram
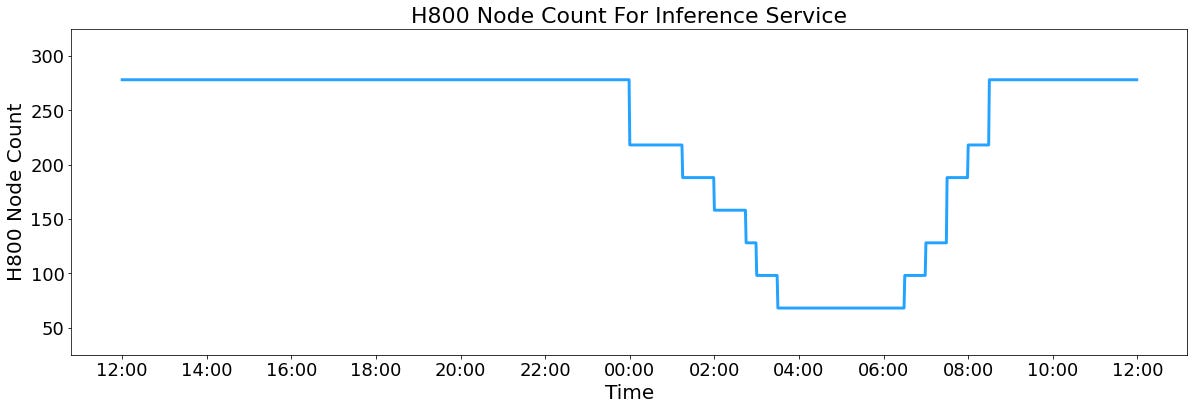
Actual statistics of online systems
All services of DeepSeek V3 and R1 use H800 GPU and the same precision as training. That is, matrix calculation and dispatch transmission use the same FP8 format as training, and core-attention calculation and combine transmission use the same BF16 format as training, which guarantees the service effect to the greatest extent.
In addition, since the service load is high during the day and low at night, Deepseek have implemented a mechanism to deploy inference services with all nodes when the load is high during the day. When the load is low at night, reduce the inference nodes to use for research and training. In the last 24 hours (2025/02/27 12:00 to 2025/02/28 12:00 Beijing time), the total number of nodes occupied by DeepSeek V3 and R1 inference services was 278 nodes at peak and 226.75 nodes on average (8 H800 GPUs per node). Assuming the GPU rental cost is $2/hour, the total cost is $87,072/day.
During the 24-hour statistical period, DeepSeek V3 and R1:
- The total number of input tokens is 608B, of which 342B tokens (56.3%) hit the KVCache disk cache.
- The total number of output tokens is 168B. The average output rate is 20~22 tps, and the average KVCache length of each output token is 4989.
- The average throughput of each H800 is: for the prefill task, the input throughput is about 73.7k tokens/s (including cache hits); for the decode task, the output throughput is about 14.8k tokens/s.
The above statistics include all loads of the website, APP and API. If all tokens are calculated according to the pricing of DeepSeek R1 , the total revenue per day is theoretically $562,027, with a cost-profit ratio of 545%.
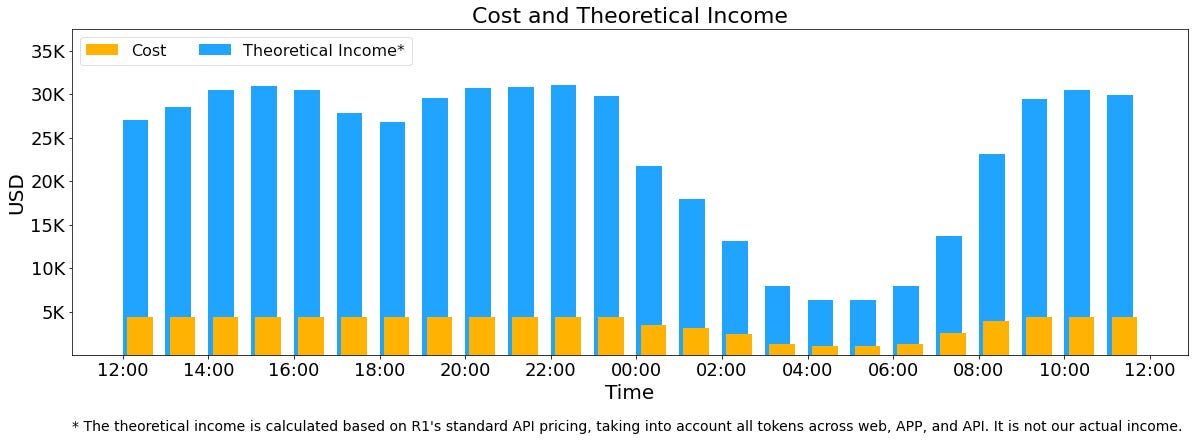
Of course Deepseek doesn't actually have that much revenue, because V3 is priced lower, and paid services only account for a part of it, and there are also discounts at night.
refer to
- ^ Pricing for DeepSeek R1: $0.14/million input tokens (cache hits), $0.55/million input tokens (cache misses), $2.19/million output tokens.
Comments
Post a Comment