Last Friday, DeepSeek tweeted that this week will be Open Source Week, and it will open source five software libraries in succession.
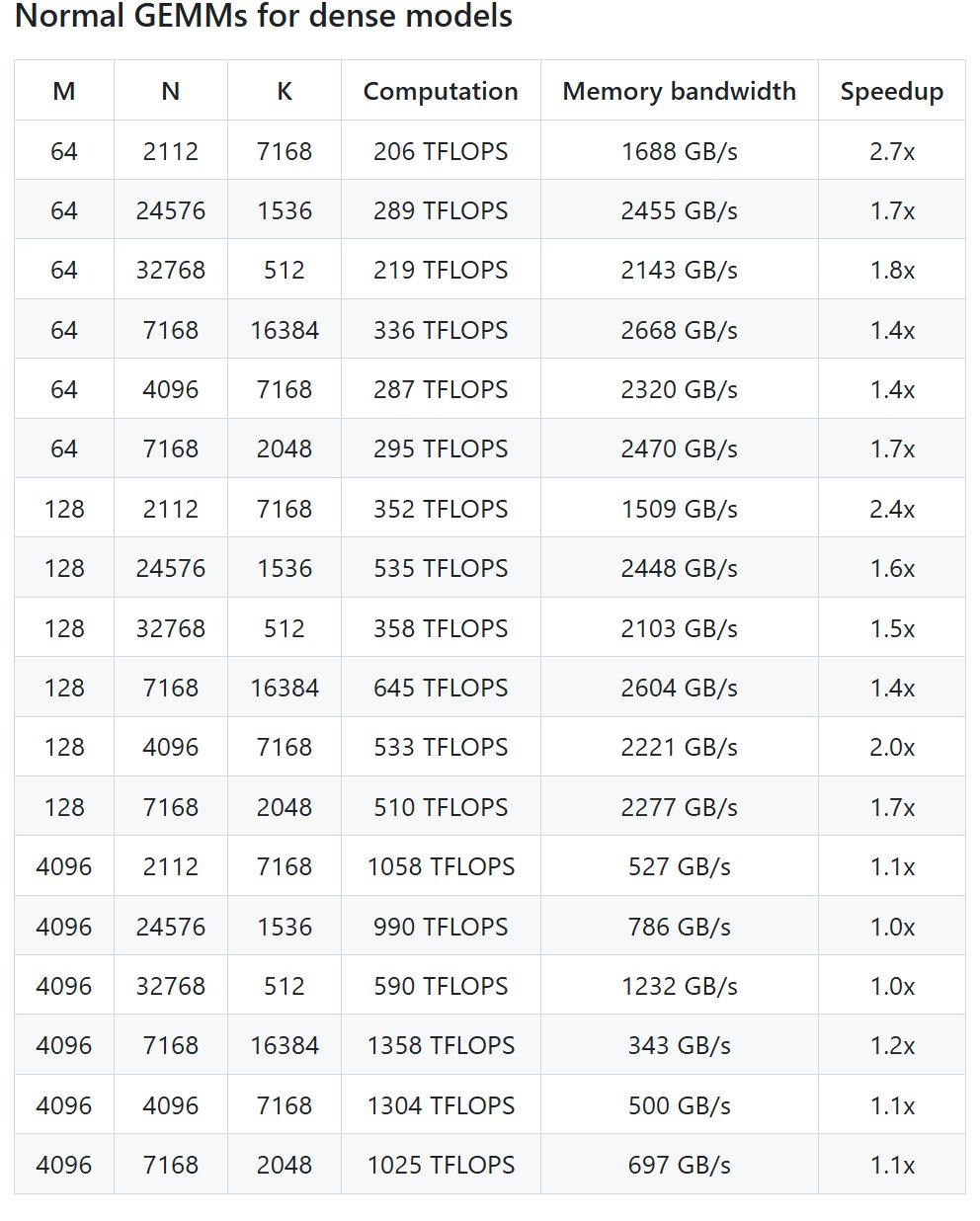
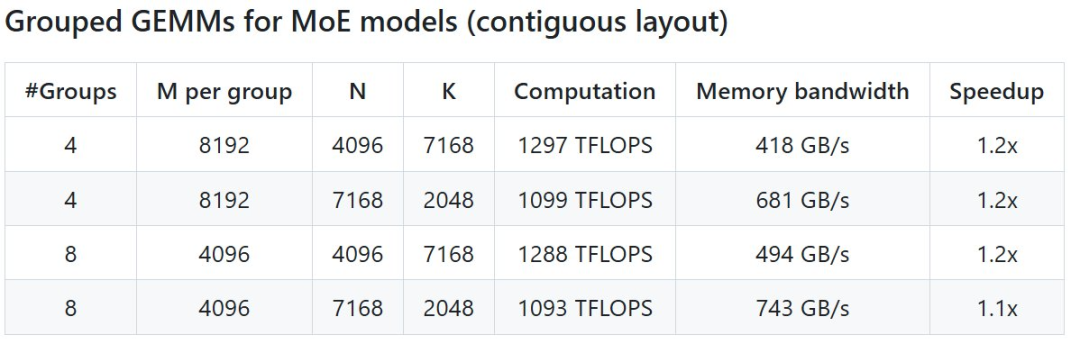
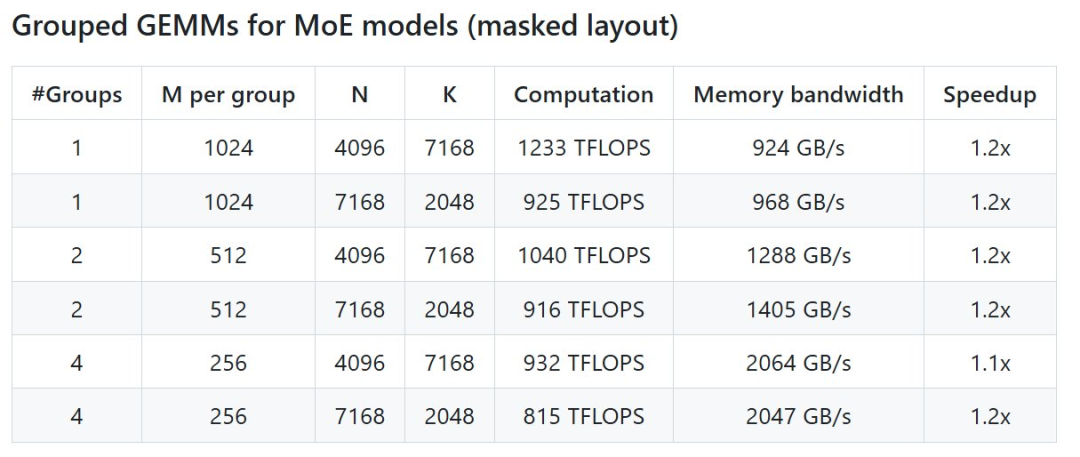
On the first day, they open-sourced an efficient MLA decoding core for Hopper GPU: FlashMLA .The next day, they open-sourced the first open-source EP communication library designed specifically for MoE (Mixture of Experts) model training and inference: DeepEP .Just now, DeepSeek's third-day open source project DeepGEMM was officially released.DeepGEMM, a FP8 GEMM library supporting dense and mixture of experts (MoE) GEMMs, provides support for training and inference for V3/R1.With only 300 lines of code, the DeepGEMM open source library can achieve 1350+ FP8 TFLOPS of computing performance on the Hopper GPU, surpassing the expert-tuned matrix computing kernels and bringing significant performance improvements to AI training and reasoning.
Specifically, DeepGEMM is a library designed to implement concise and efficient FP8 general matrix multiplication (GEMM), which adopts the fine-grained scaling technology proposed in DeepSeek-V3.The library supports both normal GEMMs as well as Mixture of Experts (MoE) grouped GEMMs. The library is written in CUDA and does not require compilation during installation, but instead compiles all kernels at runtime through a lightweight Just-In-Time (JIT) module.Currently, DeepGEMM only supports NVIDIA Hopper tensor cores. To solve the problem of inaccurate accumulation of FP8 tensor cores, it uses the two-level accumulation (promotion) mechanism of CUDA cores.Although DeepGEMM borrows some concepts from CUTLASS and CuTe, it avoids over-reliance on their templates or algebraic systems.Instead, the library is designed with simplicity in mind, consisting of only one core kernel function with only 300 lines of code . This makes it an ideal starting resource for learning about Hopper FP 8 matrix multiplication and optimization techniques.Despite its lightweight design, DeepGEMM performs as well as or better than expert-tuned libraries on a wide range of matrix shapes.Open source address: https://github.com/deepseek-ai/DeepGEMMDeepSeek has tested all possible shapes used in DeepSeek-V3/R1 inference (including pre-filling and decoding, but excluding tensor parallelism) on H800 using NVCC 12.8, and can achieve up to 2.7x speedup. All speedup indicators are based on the internally optimized CUTLASS 3.6 implementation.But according to the project, DeepGEMM does not perform well on certain shapes.First, you need these configurations- Hopper architecture GPUs must support sm_90a;
- CUDA 12.3 or higher, but for best performance, DeepSeek strongly recommends 12.8 or higher;
- CUTLASS 3.6 or higher (clonable via Git submodule).
After the configuration is complete, it is deployed:# Submodule must be clonedgit clone --recursive git@github.com:deepseek-ai/DeepGEMM.git# Make symbolic links for third-party (CUTLASS and CuTe) include directoriespython setup.py develop# Test JIT compilationpython tests/test_jit.py# Test all GEMM implements (normal, contiguous-grouped and masked-grouped)python tests/test_core.py
Finally, import deep_gem in your Python project and you can use it.For more information, see the GitHub open source repository.Reuters: DeepSeek R2 large model is ahead of schedule again, to be released before MayWhile DeepSeek is working hard to open source its data, people are also looking for information about the company's next-generation large model. Last night, Reuters suddenly broke the news that DeepSeek may release the next-generation R2 model before May, which has attracted attention.According to multiple people familiar with the matter, DeepSeek is accelerating the release of subsequent versions of the R1 strong reasoning large model. Two of them said that DeepSeek originally planned to release R2 in early May, but now hopes to release it as soon as possible. DeepSeek hopes that the new model will have more powerful code generation capabilities and be able to reason about languages other than English.Perhaps the next release of DeepSeek will be another critical moment for the AI industry.


Comments
Post a Comment